

نحوه تغییر باند وای فای WiFi بین 2GHz و 5GHz در ویندوز 10
سرعت اینترنت گاهی اوقات می تواند بسیار مشکل ساز باشد و هیچ کس این را نمی خواهد.

چه دانشجو باشید و چه حرفه ای، اینترنت بد قطعا روحیه شما را خراب می کند. کارهای متفاوتی وجود دارد که می توانید انجام دهید تا اطمینان حاصل کنید که سرعت اینترنت خوبی دارید. تغییر باند وای فای یکی از این موارد این است که می توانید باندهای Wi-Fi را در رایانه خود تغییر دهید. در این آموزش، نحوه تغییر بین باندهای WiFi 2.4GHz و 5GHz در Windows 10 را به شما نشان خواهم داد.
تغییر بانید بین WiFi 2.4Ghz و 5GHz
خب، چرا باید باندهای Wi-Fi را تغییر دهید؟ اگر روتر یا مودم شما دارای فرکانس 5 گیگاهرتز است و رایانه شما دارای آداپتور مشابه است، سرعت اینترنت بهتری خواهید داشت.
با این حال، گاهی اوقات رایانه شما قادر به تشخیص باند 5GHz نیست و شما بطور خودکار از باند 2.4GHz استفاده می کنید. برخی از رایانه ها می توانند از دو باند 2.4GHz و 5GHz استفاده کنند و شما می توانید آن را مجبور به استفاده از دومی کنید. ابتدا باید مشخص کنید که چه باندهایی در رایانه شما پشتیبانی می شوند.
بررسی باندهای قابل پشتیبانی
وای فای 2.4 گیگاهرتز می تواند مساحت وسیعی را پوشش دهد و بتواند در اشیا و دیوارهای محکم نفوذ کند. وای فای 5 گیگاهرتزی به شما سرعت 1 گیگابیت بر ثانیه می دهد.
گام 1#: به منوی Start برید و CMD را تایپ کنید. و Open را بزنید.



گام 2#: دستور زیر را تایپ کنید دکمه Enter را بزنید.
گام 3#: به گزینه Radio types supported توجه کنید:

- 802.11g و 802.11n به معنی این است که سیستم شما فقط از 2.4GHz پشتیبانی میکند.
- 802.11n, 802.11g, و 802.11b به معنی این است که سیستم شما فقط از 2.4GHz پشتیبانی میکند.
- اگر مولتی بانده از جمله 802.11a یا 802.11ac نوشته شده باشه، به این معنی است که سیستم شما از دو باند 2.4GHz و 5GHz پشتیبانی می کند.
تغییر باند وای فای
- روی Start راست کلیک کنید، یا کلید ترکیبی Win+X رو بفشارید.
- گزینه Device Manager را انتخاب کنید
- در صفحه باز شده گزینه Network Adapters رو انتخاب کنید تا زیر گزینه های آن مشخص شوند.

4. روی گزینه آداپتور وای فای راست کلیک کنید و Properties را انتخاب کنید.
5. تب Advanced را انتخاب کنید.
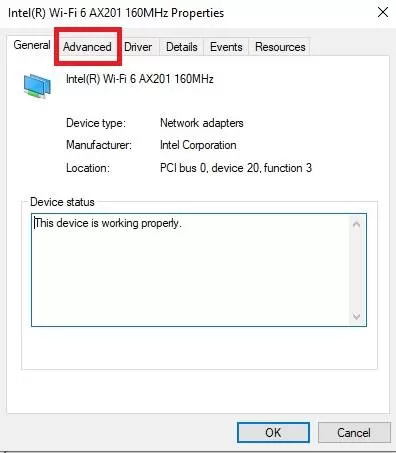
6. در بخش Property گزینه Preferred Band رو انتخاب کنید.
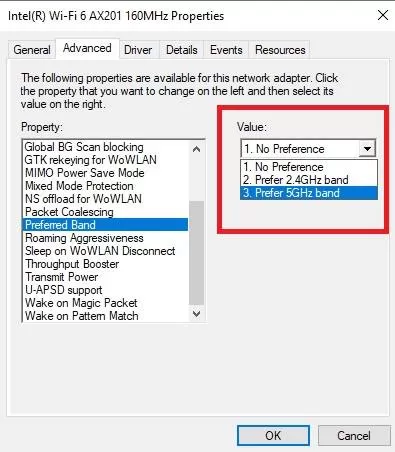
7. در قسمت Value گزینه Prefer 5GHz band رو انتخاب کنید و دکمه OK رو بزنید.
بیشتر بخوانید:



